DiFlow-TTS:
Compact and Low-Latency Zero-Shot Text-to-Speech with Factorized Discrete Flow Matching
Abstract. This paper introduces DiFlow-TTS, a novel zero-shot text-to-speech (TTS) system that employs discrete flow matching for generative speech modeling. We position this work as an entry point that may facilitate further advances in this research direction. Through extensive empirical evaluation, we analyze both the strengths and limitations of this approach across key aspects, including naturalness, expressive attributes, speaker identity, and inference latency. To this end, we leverage factorized speech representations and design a deterministic Phoneme-Content Mapper for modeling linguistic content, together with a Factorized Discrete Flow Denoiser that jointly models multiple discrete token streams corresponding to prosody and acoustics to capture expressive speech attributes. Experimental results demonstrate that DiFlow-TTS achieves strong performance across multiple metrics while maintaining a compact model size, up to 11.7 times smaller, and enabling low-latency inference that is up to 34 times faster than recent state-of-the-art baselines.
Contents
Note- DiFlow-TTS (ours): All audio samples on this demo page were generated by DiFlow-TTS (NFE=128), trained on 470 hours of the LibriTTS dataset.
- MaskGCT: All audio samples on this demo page were generated using the official code and a pre-trained checkpoint, trained on English and Chinese data from Emilia, each with ~50K hours (≈100K hours total).
- VoiceCraft: All audio samples on this demo page were generated using the official code and a pre-trained checkpoint, trained on 9K hours of the GigaSpeech dataset.
- NaturalSpeech 2: All audio samples on this demo page were generated using the Amphion toolkit and a pre-trained checkpoint, trained on 585 hours of the LibriTTS dataset.
- VALL-E: All audio samples on this demo page were reproduced using the Amphion toolkit on 500 hours of the LibriTTS dataset.
- F5-TTS: All audio samples on this demo page were reproduced using the official code and trained on 500 hours of the LibriTTS dataset.
- OZSpeech: All audio samples on this demo page were generated using the official code and a pre-trained checkpoint, trained on 500 hours of the LibriTTS dataset.
Model Overview
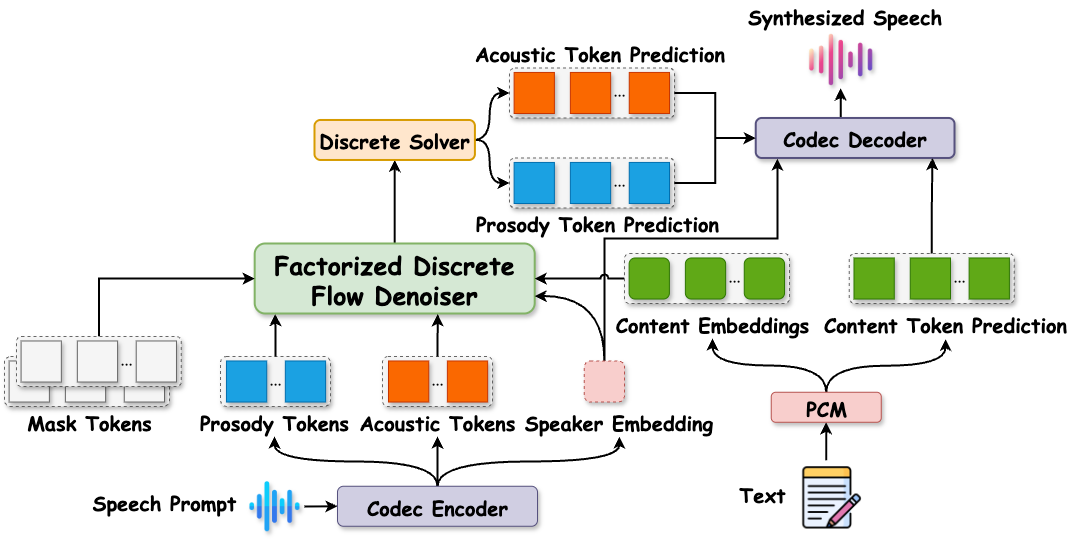
Figure 1. Overview of DiFlow-TTS. A Codec Encoder decomposes the speech prompt into speaker, prosody, and acoustic tokens, while the Phoneme-Content Mapper (PCM) converts text into content embeddings. Conditioned on these, the Factorized Discrete Flow Denoiser (FDFD) generates prosody and acoustic tokens, and the Codec Decoder reconstructs the waveform.
Detailed Model
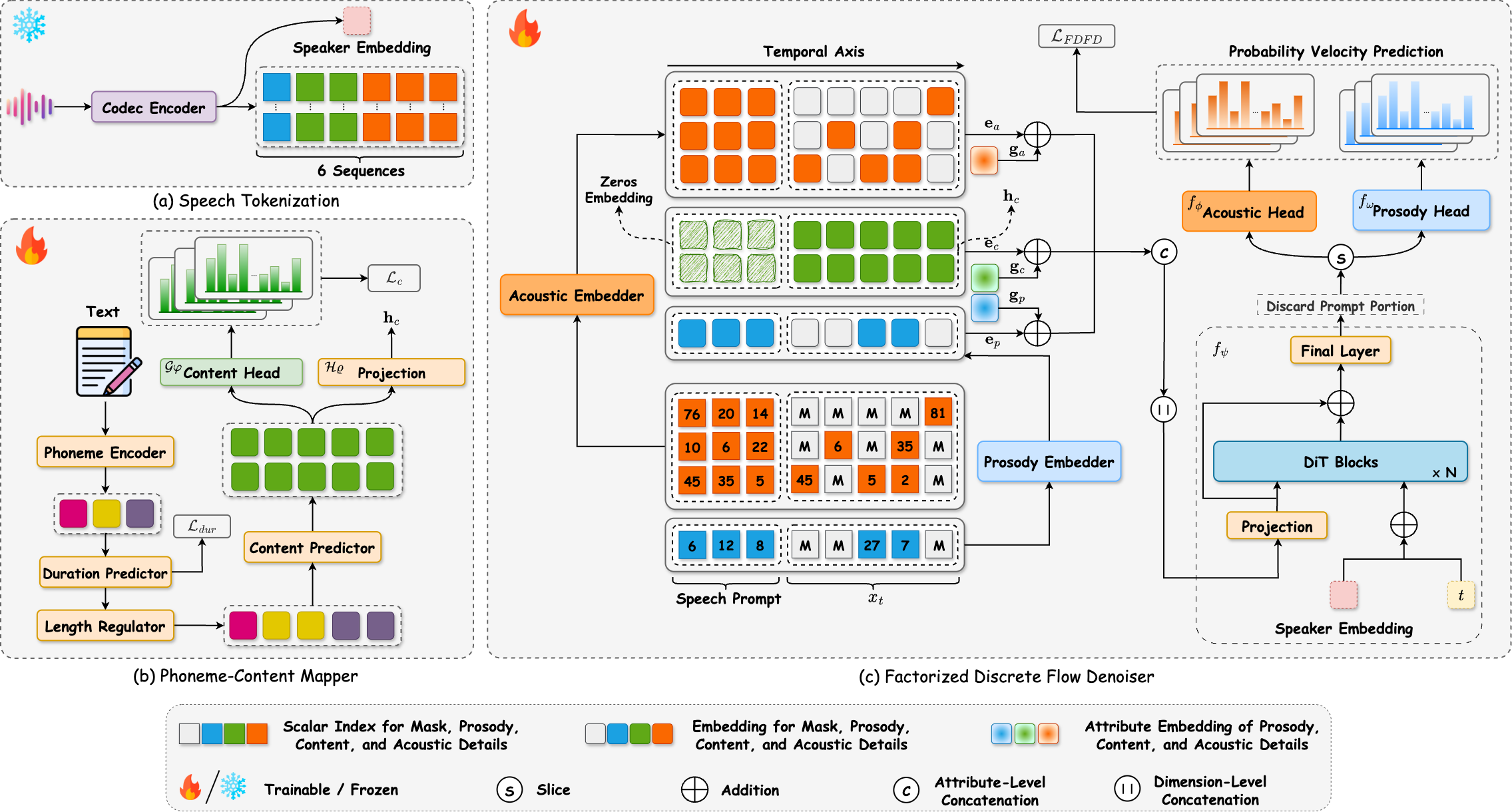
Figure 2. The detailed architecture of DiFlow-TTS comprises three main components: (a) Speech Tokenizer, which extracts factorized discrete tokens and a speaker embedding from a raw speech; (b) Phoneme-Content Mapper, which maps input phonemes to discrete content tokens and generates the corresponding content embeddings; and (c) Factorized Discrete Flow Denoiser, which performs discrete flow matching conditioned on the content embeddings, speaker embedding, and the discrete prosody and acoustic tokens derived from the reference speech prompt.
Zero-shot TTS (Celebrities)
DiFlow-TTS is capable of mimicking celebrity voices. The following examples are provided strictly for research purposes.
| Celebrity | Target Transcript | Prompt | DiFlow-TTS (ours) |
|---|---|---|---|
| Donald Trump | But to those who knew her well, it was a symbol of her unwavering determination and spirit. | From Spark-TTS's Demo |
|
| Optimus Prime | I don't really care what you call me. I've been a silent spectator, watching species evolve, empires rise and fall. But always remember, I am mighty and enduring. Respect me and I'll nurture you; ignore me and you shall face the consequences. | From DiTTo-TTS's Demo |
|
| Benedict Cumberbatch | The best love is the kind that awakens the soul and makes us reach for more, that plants a fire in our hearts and brings peace to our minds. And that's what you've given me. That's what I'd hoped to give you forever. | From DiTTo-TTS's Demo |
|
| Mark Zuckerberg | It is our choices that show what we truly are, far more than our abilities. | From DiTTo-TTS's Demo |
Zero-shot TTS (LibriSpeech)
All speakers are unseen during training. The audio samples are drawn from the LibriSpeech test-clean dataset, using audio prompt lengths of 1s, 3s, and 5s.
| Prompt Duration | Target Transcript | Prompt | DiFlow-TTS (ours) | MaskGCT | VoiceCraft | NaturalSpeech 2 | VALL-E | F5-TTS | OZSpeech |
|---|---|---|---|---|---|---|---|---|---|
| 1 second | therefore her majesty paid no attention to anyone and no one paid any attention to her. | Not supported (min. 3s prompt) |
|||||||
| he often stopped to examine the trees nor did he cross a rivulet without attentively considering the quantity the velocity and the color of its waters. | Not supported (min. 3s prompt) |
||||||||
| as used in the speech of everyday life the word carries an undertone of deprecation. | Not supported (min. 3s prompt) |
||||||||
| i stood with my back to the wall for i wanted no sword reaching out of the dark for me. | Not supported (min. 3s prompt) |
||||||||
| i wanted nothing more than to see my country again my friends my modest quarters by the botanical gardens my dearly beloved collections. | Not supported (min. 3s prompt) |
||||||||
| 3 seconds | as soon as these dispositions were made the scout turned to david and gave him his parting instructions. | ||||||||
| in both these high mythical subjects the surrounding nature though suffering is still dignified and beautiful. | |||||||||
| the meter continued in general service during eighteen ninety nine and probably up to the close of the century. | |||||||||
| that is the best way to decide for the spear will always point somewhere and one thing is as good as another. | |||||||||
| there came upon me a sudden shock when i heard these words which exceeded anything which i had yet felt. | |||||||||
| 5 seconds | after proceeding a few miles the progress of hawkeye who led the advance became more deliberate and watchful. | ||||||||
| he had preconceived ideas about everything and his idea about americans was that they should be engineers or mechanics. | |||||||||
| as used in the speech of everyday life the word carries an undertone of deprecation. | |||||||||
| so no tales got out to the neighbors besides it was a lonely place and by good luck no one came that way. | |||||||||
| as soon as these dispositions were made the scout turned to david and gave him his parting instructions. |
Emotion
DiFlow performs reasonably well in mimicking emotions from reference speech prompts, even though it was mainly trained on neutral emotional data.
| Emotion | Target Transcript | Prompt | DiFlow-TTS (ours) |
|---|---|---|---|
| Angry | You said you'd always be there, but now I'm standing here alone! | ||
| Disgust | |||
| Happy | |||
| Sad | |||
| Calm |